

AI算力集群正加速向万卡、十万卡级规模迭代。作为算力高效释放的“神经枢纽”,高速互连网络的性能、扩展性与稳定性直接决定了集群的整体效能。大规模集群组网需兼顾高带宽、低延迟与无损传输,同时要适配算力指数级增长的扩展需求,还要控制组网成本与故障风险。现有方案难以全面平衡这些核心诉求。
中科曙光历经三年攻坚推出的scaleFabric,作为国内首款类InfiniBand原生无损RDMA高速网络,精准直击行业难点,为超大规模集群筑牢高效稳定的网络底座。

▍ 性能对标国际主流,夯实组网硬实力
在技术指标和性能层面,scaleFabric的带宽与延迟指标对齐国际主流产品。交换芯片端口密度达到80口400G,较同类产品提升25%,为scaleX万卡超集群提供了高可扩展组网支撑。
更关键的是,scaleFabric沿用与InfiniBand一致的信用流控及链路层重传机制,实现真正无损传输。相较RoCE网络,更适配超大规模智算场景,可实现即插即用,大幅降低用户优化成本。
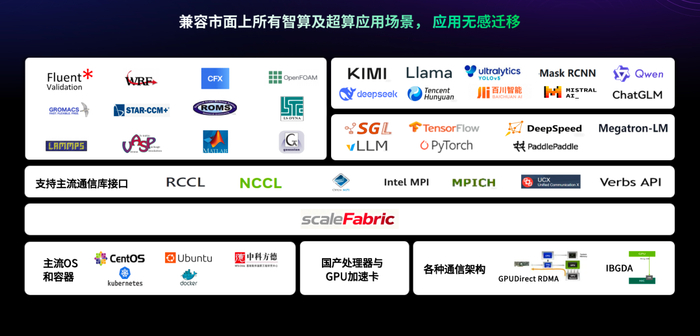
▍ 生态兼容+扩展突破,释放核心实用价值
在应用生态方面,scaleFabric提供原生RDMA verbs接口,完美兼容现有InfiniBand应用生态,让并行计算、大模型训练与推理等应用无需修改代码即可无缝迁移,实现应用无感适配。
在超大规模扩展能力上,scaleFabric突破了InfiniBand协议五万卡级的局限,单子网支持超十万卡扩展。通过多轨技术,可实现百万卡级集群部署,契合AI算力指数级增长需求。这一优势已在scaleX万卡超集群中得到验证,支撑系统总算力突破5EFlops。
▍ 自主创新赋能,兼顾可靠与成本优势
面对高端SerDes IP“卡脖子”困境,曙光自研112G PAM4高速SerDes IP,从底层保障复杂环境下的信号可靠性。针对光模块故障痛点,研发了毫秒级链路故障路由恢复技术,且恢复时间不随网络规模增长而延长。
配合数字孪生运维系统,集群可用性提升至99.99%。同时,依托端口密度优势,scaleFabric的组网成本较InfiniBand降低约30%,打破高端网络高成本的桎梏。
scaleFabric的发布不仅填补了国内原生RDMA网络的技术空白,更开启了InfiniBand网络国产化替代的新篇章。曙光秉持开放架构理念,向合作伙伴共享技术成果,推动产业链协同创新,加速我国超算与智算产业自主化进程。
https://finance.sina.com.cn/roll/2026-01-20/doc-inhhyfup7054593.shtml






